开场白
您好,我叫XX.统招本科毕业于XX,有6年开发经验,2年管理经验,从0到1构建多个项目,可带3-5人小团队.具有独立完成复杂工作,指导初中级开发的能力.同时熟悉系统设计、性能优化、敏捷开发. 在上⼀个公司我参与了中国山东网项目开发,主要职责是对开源框架进行微服务改造,核心业务模块拆分以及负责开发一些与平台运营相关的系统.
集合
- List | ArrayList | LinkedList | CopyOnWriteArrayList
- Set | HashSet | LinkedHashSet | TreeSet
- Queue | PriorityQueue | BlockingQueue | DelayQueue
- Map | HashMap | LinkedHashMap | ConcurrentHashMap
多线程
- 线程的生命周期和状态
- 死锁 | 避免死锁
- Java 内存模型
- volatile
- 乐观锁与悲观锁
- synchronized
- ReentrantLock | Condition
- ReentrantReadWriteLock | StampedLock
- ThreadLocal
- 线程池 | ThreadPoolExcutor | 参数
- 常见并发容器
- AQS | 常见同步工具类
- Semaphore (permits accquire(permits–) release(permits++) ) 使用场景:控制并发访问量和单机限流
- CountDownLatch (count countdown(count–) await(count==0)) 使用场景:并行任务和同步操作
- CyclicBarrier (parties await)
使用场景:主要应用场景和
CountDownLatch类似
- Atomic | CAS算法 Unsafe.compareAndSwap native
- CompletableFuture
JVM
内存区域
- 堆 + 字符串常量池 (对象实例 + 字符串)
- 程序计数器 (1. 字节码解释器改变程序计数器来依次读取指令,实现流程控制 2. 记录线程执行的位置)
- 栈 (栈帧–> 局部变量表 + 操作数栈(中间计算结果) + 动态链接(调用其他方法时,将符号引用转化为直接引用) + 方法返回地址)
- 本地方法栈 (native方法 同栈帧)
- 方法区(元空间(类信息 + 字段信息 + 方法信息 + 静态变量 + 常量 + JIT编译后的代码缓存) + 运行时常量池(类符号引用 + 字段符号引用 + 方法符号引用 + 接口方法符号))
- 本地内存
类创建过程
加载(类加载器加载)
连接
验证(验证 class文件格式检查 字节码语义检查 程序语义检查 类正确性检查)
准备(分配内存 初始化零值 设置对象头(类的元数据 哈希码 GC分代年龄 是否启用偏向锁))
解析(将运行时常量池符号引用替换为直接引用,得到类、字段、方法在内存中的指针或偏移量)
初始化(clinit() 调用构造方法)
卸载(类的class对象被GC)
- 实例对象被GC
- 没有被引用
- 类加载器被GC (BootstrapClassLoader,ExtClassLoader,AppClassLoader 不会被GC)
死亡对象判断算法 (引用计数 + 可达性分析)
GC ROOTS对象:
- 成员对象
- 静态对象
- 常量对象
- 实例对象
- 同步锁持有对象
- native对象
引用类型
强引用 不会被GC
弱应用 被发现就会被GC
软引用 内存不足,就会被GC
虚引用 随时会被GC
垃圾收集算法
- 标记 - 清除 (先标记存活对象,标记完成后后清除剩余对象)
- 复制 (腾出一半空间,将可用对象复制到这片空间,然后清除另一半的空间)
- 标记 - 整理 (标记存活对象,然后向一端移动,清理端边界以外的对象)
垃圾收集器 (Serial + Serial Old | Paraller New (Paraller Scavenge + Paraller Old) | CMS (初始标记 -> 并发标记 - > 重新标记 -> 并发清除)| G1 | ZGC)
类加载过程
- 加载 根据全类名找到二进制数据,转换成方法区结构,生成一个Class对象作为方法区入口
- 验证 class文件格式检查 字节码语言检查 程序语义检查 类正确性检查
- 准备 分配内存 初始化零值 设置对象头
- 解析 常量池中符号引用转化成直接引用,获取类和字段在内存中的偏移量
- 初始化 执行clinit方法
- 使用
- 卸载 被GC回收/该类的所有实例对象被GC/该类的类加载器的实例被GC/该类没有被任何地方引用
类加载器 | 破坏双亲委派
JVM参数 以及 线上排查问题思路
GC日志记录
-XX:+PrintGCDetails:打印基本 GC 信息-XX:+PrintGCDateStamps:打印 GC 日期信息-XX:+PrintTernuringDistribution:打印对象分布-XX:+PrintHeapAtGC:打印堆数据-XX:+PrintReferenceGC:打印Reference处理信息-XX:+PrintGCApplicationStoppedTime:打印Stop The World的时间-XX:+PrintSafepointStatistics:打印safepoint信息-XX:PrintSafepointStatisticsCount=1:1个safepoint-Xloggc:/path/to/gc-%t.log:GC日志输出文件的文件路径-XX:+UseGCLogFileRotation:开启日志文件分割-XX:NumberOfGCLogFiles=14:最多分割几个文件,超过之后就从头开始写-XX:GCLogFileSize=50M:每个文件大小上限
处理OOM
-XX:+HeapDumpOnOutOfMemoryError:遇到OOM时将heap转储到物理文件中-XX:HeapDumpPath=./java_pid<pid>.hprof:写入文件的路径-XX:OnOutOfMemoryError="< cmd args >;< cmd args >":当内存不足时会执行命令-XX:+UseGCOverheadLimit:限制GC花费的VM时间比例
线上示例
设置应用的元空间大小、堆内存大小、新生代大小、栈大小、Eden区和Survivor区比例
1ENV JAVA_OPTS="-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xms512m -Xmx512m -Xmn128m -Xss256k -XX:SurvivorRatio=8"以服务器模式启动、禁止系统调用System.gc()、使用ParNewGC为新生代垃圾回收器、CMS为老年代垃圾回收器、老年代使用的空间达到 70% 时就开始垃圾回收、 CMS 垃圾回收时卸载不再需要的类、并行处理软引用、弱引用和虚引用、在 CMS 的 remark 阶段之前进行一次 young generation 垃圾回收、出现内存溢出错误时导出堆信息、打印垃圾回收的详细信息,包括每次垃圾回收的详细情况、时间戳、堆的情况、应用暂停的时间等
1 2 3 4ENV JAVA_FIXED_ARGS="-server -XX:+DisableExplicitGC -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly\ -XX:CMSInitiatingOccupancyFraction=70 -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses -XX:+CMSClassUnloadingEnabled\ -XX:+ParallelRefProcEnabled -XX:+CMSScavengeBeforeRemark -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintGCDetails\ -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCDateStamps"设置JVM错误文件的路径地址(%p = pid)、发生OOM转储文件的路径、垃圾回收日志的路径(%t=timestamp)
1 2ENV JAVA_GC_LOG_PATH="-XX:ErrorFile=/var/applog/gc/starfish-info-backend/hs_err_pid%p.log -XX:HeapDumpPath=/var/applog/gc/starfish-info-backend\ -Xloggc:/var/applog/gc/starfish-info-backend/gc%t.log"设置环境变量为生产环境
1ENV PARAMS="--spring.profiles.active=prod"Dockerfile启动java进程的命令
1 2ENTRYPOINT ["sh", "-c", "java -Dloader.path=/app/libs/ -Djava.security.egd=file:/dev/./urandom -Dfile.encoding=UTF-8\ $JAVA_OPTS $JAVA_FIXED_ARGS $JAVA_GC_LOG_PATH -jar /app/app.jar $PARAMS"]
堆结构:
| 新生代 | 老年代 | 元空间 | 本地内存 |
|---|---|---|---|
| Eden | S0 |S1 | Ternured | MetaSpace(初始20.8m) | 代码缓存 + Thread (线程私有) |
| -XX:NewSize=2048M | |||
| -XX:MaxNewSize=3096M | |||
| -Xmn2048m | |||
| -XX:NewRatio=1 (老年代:新生代 = 1:1) | |||
| -Xms8G | -Xms8G | ||
| -Xmx8G | -Xmx8G | ||
| -XX:MetaspaceSize=512m | |||
| -XX:MaxMetaspaceSize=512m | |||
| -Xss256k(栈大小) |
Spring Spring MVC SpringBoot
Spring IOC & Spring AOP
- IOC: 将创建对象的控制权交给Spring容器
- AOP: 在程序执行过程中动态织入代码,实现对横切关注点的模块化管理
Spring 核心流程图 (创建Bean过程)
- 根据注解或配置文件获取Bean的定义
- 通过反射创建Bean的实例
- 通过set方法设置属性
- 如果实现了BeanNameAware|BeanClassLoaderAware|BeanFactoryAware接口,则调用对应的set方法
- 如果实现了BeanPostProcessor接口,则调用postProcessorBeforeInitialization()方法
- 如果实现了InitializingBean接口,则调用afterPropertiesSet方法
- 如果指定了init-method方法,则执行指定方法
- 如果实现了BeanPostProcessor接口,则调用postProcessorAfterInitialization()方法
- 使用Bean
- 如果实现了DisposableBean接口,则调用destory()方法
- 如果指定了destory-method方法,则执行指定方法
Spring AOP通知方式
- 前置通知
- 后置通知
- 返回通知
- 异常通知
- 环绕通知
Spring 管理事务方式| 隔离级别 | 传播行为
- 事务管理方式:
- 编程式: TransacationManager手动提交
- 声明式: xml|注解 (@Transactional) 自动提交
- 隔离级别:
- 采用数据库的隔离级别 (Default)
- 读未提交 (Read Uncommited)
- 读已提交 (Read Commited)
- 可重复读 (MySQL数据库的默认隔离级别 Repetable Read)
- 串行化 (Serializable)
- 传播行为:
- Requried:必须要有一个事务,没有就创建
- Requried_New:必要需要有一个事务,有也创建
- Support: 可以有一个事务,没有就以非事务运行
- Not_Support: 有没有都以非事务运行
- Mandatory: 必须要有一个事务,没有就抛异常
- Never: 绝对不能有事务,有就抛异常
- Nested: 有就嵌套事务,没有就创建
- 事务管理方式:
Spring MVC 流程
- 客户端请求,DispatcherServlet拦截请求
- DispatcherServlet调用HandlerMapping,HandlerMapping根据请求路径找到对应的Handler
- DispatcherServlet调用HandlerAdapter执行Handler
- Handler处理完请求后,返回ModelAndView给DispatcherServlet,Model是返回的数据对象,View是逻辑视图
- DispatcherServlet调用ViewResolver对逻辑视图进行解析,找到真正的视图
- DispatcherServlet把返回的Model传给视图进行渲染
- 把渲染后的视图返回响应
SpringBoot 常用注解 自动装配原理
常用注解: @SpringBootApplication (@ComponetScan @Configuration @EnableAutoConfiguration = @Import( AutoConfigurationImportSelector))
自动装配原理: SpringBoot通过@EnableAutoConfiguration注解实现了自动装配,@EnableAutoConfiguration通过AutoConfigurationImportSelector的getAutoConfigurationEntry方法,使用SpringFactoryLoader加载META-INF/Spring.factories文件,获取EnableAutoConfiguration指定的类,并过滤掉不满足Condition的类,实现自动装配.
什么是SpringBootStarter 自定义Starter
- starter是为SpringBoot提供一套快速的默认配置的机制,使用SpringFactoryLoader实现.
- 实现自定义starter需要: 1.导入Spring依赖 2.自定义配置类 3.编写META-INF/spring.factories,指定enableAutoConfiguration要加载的类
spring循环依赖怎么解决(说出三级缓存源码细节)
- SingletonObjects 一级缓存 存放成品Bean
- EarlySingletonObjects 二级缓存 存放过渡Bean包括原始Bean和代理Bean
- SingletonFactories 三级缓存 存放ObjectsFactory对象,实际使用getEarlyBeanReference()方法获取原始Bean或代理Bean
如果是只有两级缓存,代理Bean每次生成的对象会不一样,不满足Spring单例原则.
2.6.X版本默认关闭循环依赖,如需开启在配置文件中指定spring.main.allow-circular-references=true
前置条件:对象是单例的且开启了循环依赖,默认会将未初始化完成的Bean放入三级缓存中,循环依赖的对象会从三级缓存中找到依赖的对象,并在三级缓存销毁,放入二级缓存中.等初始化完成就从二级缓存中销毁,放入一级缓存中.
MySQL
- MySQL基础架构
- 连接器
- 查询缓存
- 分析器
- 优化器
- 执行器
- 存储引擎
- MySQL存储引擎
- MyISAM | InooDB 区别如下
- MyISAM不支持事务,InooDB支持事务
- MyISAM和InooDBd都使用B+树作为数据结构,但实现方式不一样
- MyISAM只有表锁,InooDB有行锁,表锁,读锁,写锁,MVCC等
- MyISAM只有非聚簇索引,InooDB既有聚簇索引也有非聚簇索引
- MyISAM不支持外键,InooDB支持外键
- MyISAM不支持崩溃恢复,InooDB可以依赖redo log恢复数据
- MyISAM | InooDB 区别如下
- MySQL索引
- 聚簇索引 | 非聚簇索引
- 主键索引 | 普通索引,唯一索引,外键索引,联合索引,全文索引
- 最左前缀匹配原则: 使用联合索引时,有最左匹配原则,即从左往右,依次匹配
- 索引下推: 即将查询条件进行优化,直接过滤掉不满足条件的记录
- 为什么选择B+树作为索引的数据结构,有什么优点: IO查询稳定,范围查询更快.
- 一个高度为3的B+树最多能存多少条记录:
记录数 = 根节点指针数 * 单个叶子节点记录数 = 161024/(6(InnoDB指针大小)+4(int主键大小)/8(bigint主键大小)) * (16kb(页大小)/1kb(单条数据最大长度)) = 161024/10(14) (一层容量指针数) * 16*1024/10(14) (二层容量指针数) * 16 = 1170 * 1170 * 16 = 21,902,400
- 如果走辅助索引,最多需要经过几次IO: 3层 找到主键 再3层 找到数据 = 6次
- MySQL日志
- undo log
- 存放所有事务进行修改前的原始数据
- 用于保证事务的原子性,另外MVCC的实现依赖于:隐藏字段和Read View以及undo log.
- redo log
- 用于保证数据库的持久性,会先通过buffer pool去读或修改数据,然后记录到redo log上,等待刷盘.
- 存在刷盘机制,0-提交事务不刷盘,等待后台线程刷盘 1-提交事务就刷盘 2-提交事务写入文件缓存,等待后台线程刷盘
- bin log
- 用于数据库备份,会记录所有涉及更新数据的逻辑操作.
- undo log
为了解决写入redo log和bin log可能会出现不一致的情况,Mysql使用两阶段提交方案解决这个问题.
- 在尚未提交事务时,会先prepare记录redo log.
- 在已提交事务时,会先写入bin log日志,然后在redo log日志进行commit,提交写入redo log.
- 即使在提交事务时,写入bin log发生异常,也不会有影响,只会回滚事务.
- 在写入redo log时发生异常,不会回滚事务,而是通过找到bin log来写入数据.
MySQL事务
- 特性: C是目的,AID是手段
- A 原则性
- C 一致性
- I 隔离性
- D 持久性
- 并发问题:
- 丢失修改: 修改操作被覆盖了
- 脏读: 读到了未提交的数据
- 不可重复读:两次读结果不一样
- 幻读: 两次读的结果变多了
- 解决方案:
- 锁
- 读锁(共享锁)
- 写锁(排他锁)
- 表锁
- 行锁
- MVCC: 多版本并发控制,版本号唯一,使用隐藏字段、Read View、Undo log实现
- 锁
- 事务隔离级别: 使用锁和MVCC共同实现
- 读未提交: 解决丢失修改
- 读已提交: 解决了丢失修改,脏读
- 可重复读: 解决了丢失修改,脏读,不可重复读
- 串行化: 解决了丢失修改,脏读,不可重复读,幻读
- 特性: C是目的,AID是手段
MySQL锁
读锁(共享锁): 锁兼容,读取时多个事务可同时获取. 一般不加锁,除非显式指定了 select … lock in share mode / select … for share
写锁(排他锁): 锁不兼容,修改时只能由一个事务获取. 一般不加锁,除非显式指定了 select … for update
表锁: 针对非索引字段加锁
行锁: 针对索引字段加锁
记录锁: Record Lock,单行记录上锁
间隙锁: Gap Lock,多行记录上锁但不包括本身
临键锁: Next-Key Lock = Record Lock + Gap Lock,多行记录上锁包括本身
RR的事务隔离级别下,行锁默认使用临键锁,但操作主键索引或唯一键索引时,会降级成记录锁
快照读: 即普通的select 语句,不加锁,读的是记录的历史版本.
当前读: 即加了读写锁的select 语句,读的是记录的当前版本.
- MVCC实现
- 读: 读当前事务开始时间的版本数据
- 写: 创建一个新的版本,写入版本数据
- 在RR隔离级别下,如果是当前读(一致性锁定读)的情况下(for update/ insert / update / delete),通过加入临键锁,锁住当前记录和范围,防止其他事务插入数据,出现幻读
- 但如果是快照读(一致性非锁定读),即使是RR隔离级别,也会出现幻读
- 读: 读当前事务开始时间的版本数据
实现方式: 隐藏字段 、 Read View 、 undo log
隐藏字段
- DB_TRX_ID : 最后一次插入或更新该行的事务id
- DB_ROW_ID: 没有设置主键且没有唯一非空索引时,使用它来充当聚簇索引
- DB_ROLL_PTR: 回滚指针,指向undo log
Read View
- 可见性判断,里面保存了"当前对本事务不可见的其他活跃性事务"
- m_low_limit_id: 目前出现过的最大的事务的ID+1,即下一个被分配事物的ID,大于等于这个ID的数据版本均不可见
- m_up_limit_id: 活跃事务列表m_ids中最小的事务ID,如果m_ids为空,则等价于m_low_limit_id.小于这个ID的数据版本均可见
- m_ids: Read View 创建时其他未提交的活跃事务的ID列表.创建Read View时,将当前未提交事务的ID记录下来,后续即使他们修改了记录行的值,对当前事务也是不可见的.m_ids不包括当前事务自己和已提交的事务.
- m_creator_trx_id: 创建该Read View的事务ID.
- 可见性判断,里面保存了"当前对本事务不可见的其他活跃性事务"
undo log
- 用于事务回滚,恢复到修改前的样子
- 用于MVCC,读历史版本的数据,实现一致性非锁定读
数据可见性算法 : …
不可重复读问题:
- RC: 每次读都会有新的Read View记录,有不可重复读问题
- RR: 事务开始时,只有第一次读有Read View记录,所以没有不可重复读问题
幻读问题:
- RR: 加入临键锁,解决幻读问题
MySQL执行计划分析
- explain + SQL
- id: 查询序号
- select_type: 查询类型,用于区分普通查询,联合查询,子查询等
- SIMPLE: 简单查询,不含UNION或子查询
- PRIMARY: 如果存在子查询,外层的SELECT标记为PRIMARY
- SUBQUERY: 子查询中的第一个SELECT
- UNION: 联合查询
- DERIVED:在 FROM 中出现的子查询将被标记为 DERIVED
- UNION RESULT: UNION的查询结果
- table:查询表名
- partitions:匹配分区
- type(重要):表的访问方法
- system:表中只有一行记录的情况下,访问方法是 system ,是 const 的一种特例
- const:表中最多只有一行匹配的记录,一次查询就可以找到,常用于使用主键或唯一索引的所有字段作为查询条件
- eq_ref: 当连表查询时,前一张表的行在当前这张表中只有一行与之对应。是除了 system 与 const 之外最好的 join 方式,常用于使用主键或唯一索引的所有字段作为连表条件
- ref: 使用普通索引作为查询条件,查询结果可能找到多个符合条件的行
- fulltext
- ref_or_null
- index_merge: 当查询条件使用了多个索引时,表示开启了 Index Merge 优化,此时执行计划中的 key 列列出了使用到的索引
- unique_subquery
- index_subquery
- range:对索引列进行范围查询,执行计划中的 key 列表示哪个索引被使用了
- index:查询遍历了整棵索引树,与 ALL 类似,只不过扫描的是索引,而索引一般在内存中,速度更快
- ALL:全表扫描
- possible_keys:查询可能用到的索引,null则可能没用到索引
- key(重要):实际用到的索引,null则没用到索引
- key_len:索引最大长度,key=null那key_len=null
- ref:当使用索引等值查询时,与索引作比较的列或常量
- rows:大致需要读取的行数,越小越好
- filtered:条件过滤后的留存记录百分比
- Extra(重要):查询的额外信息
- Using filesort: 排序时使用了外部索引进行排序,没用到内部索引进行排序
- Using temporary: 创建临时表来存储查询结果,常见于order by 或 group by
- Using index: 使用了覆盖索引,不用回表,查询效率非常高
- Using index condition: 查询优化器使用到了索引下推这个特性
- Using where: 使用where条件进行了过滤,一般在没用到索引时出现
- Using join buffer: 连表查询
- explain + SQL
MySQL优化
避免隐式转换,隐式转换(两边数据类型不一致)会导致索引失效
避免使用select * 而是使用 select 字段
避免过多join表,不超过5个
选择合适的字段类型
避免出现大事务,拆分成小事务分批提交
正确使用索引
深度分页使用范围查询、子查询、延迟关联优化
使用连续自增主键,而不是使用uuid(uuid范围查询无法排序)
Redis
Redis为什么快
- 基于内存,访问快
- 基于Reactor模型开发了一套事件处理模型,主要是单线程事件循环和IO多路复用
- 内部使用了多种优化后的数据类型,效率高
常见的读写缓存策略
- 旁路缓存模式(应用程序直接与「数据库、缓存」交互,并负责对缓存的维护)
- 读:先从缓存读,读不到由「应用程序」从数据库读取数据后返回,再把数据放入缓存
- 写:写入数据库,删掉缓存(服务端写)
- 读写穿透模式(应用程序与「缓存」交互,「缓存」与「数据库」交互,负责缓存的维护)
- 读:先从缓存读,读不到由「缓存」从数据库读,并将结果放入缓存,返回数据给应用
- 写:写入缓存,缓存不存在则更新数据库,存在则更新缓存,由「缓存」自己写数据库
- 异步缓存写入 (应用程序与「缓存」交互,「缓存」与「数据库」交互,负责缓存的维护)
- 读:先从缓存读,读不到从数据库读,再放入缓存后返回
- 写:写入缓存,不更新db,改为异步批量更新db
- 旁路缓存模式(应用程序直接与「数据库、缓存」交互,并负责对缓存的维护)
Redis应用场景
- 分布式锁
- 限流
- 消息队列
- 延时队列
- 分布式session
Redis线程模型
- 读写单线程,异步删除、网络请求多线程
- 基于Reactor模式开发了一套文件事件处理器,以单线程方式运行,以I/O多路复用来监听多个套接字
- 文件事件处理器
- 多个socket(客户端连接)
- I/O多路复用程序(支持多个连接)
- 文件事件分派器(将socket关联到事件处理器)
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
- 文件事件处理器
Redis数据结构以及应用场景
String
结构特点
SDS(Simple Dynamic String)实现,好处在于
- 可以扩容,避免缓冲区异常
- 获取字符串长度复杂度为O(1)
- 减少内存分配次数
- 二进制安全
使用场景
存储token/session/userId,序列化后的对象等
- 实现分布式锁(setnx key value)
List
- 结构特点
- 双向链表,支持反向查找和遍历
- 使用场景
- 最新文章、最新动态
- 结构特点
Set
- 结构特点
- 无序集合,类似Java中的HashSet
- 使用场景
- 网站UV统计,文章点赞/已读统计,关注
- 抽奖系统
- 结构特点
Sorted Set(Zset)
- 结构特点
- 类似TreeSet和HashMap的结合,但增加了个权重参数score,使得可以排序,还可以根据score范围查询
- 使用场景
- 排行榜
- 结构特点
BitMap
- 结构特点
- key是元素本身,value是0/1,是一个存储0/1的数组,每个value占一个bit位
- 使用场景
- 用户签到情况、活跃用户情况、是否点赞/关注
- 结构特点
HyperLogLog(基数统计)
- 结构特点
- 基数计数概率算法,并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)
- 使用场景
- 热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计
- 结构特点
Geospatial
- 结构特点
- 存储地理位置信息,基于 Sorted Set 实现
- 使用场景
- 附近的人
- 结构特点
Redis持久化机制
- 快照(snapshotting,RDB)
- 是Redis默认持久化方式,通过创建快照来获取数据在某个时间点的副本
- 默认使用bgsave进行持久化,通过创建子线程执行,而save操作会阻塞主线程
- 追加读(append-only file,AOF)
- 每条更改数据的命令会先放入缓冲区(server.aof_buf),然后写入AOF文件,最后通过fsync策略来决定何时同步到硬盘.
- AOF工作流程
- 命令追加(append): 写命令放入AOF缓冲区
- 文件写入(write):将AOF缓冲区的数据写入系统内核缓冲区
- 文件同步(fsync):AOF缓存区根据fsync策略向磁盘做同步操作,写入AOF文件
- 文件重写(rewrite):AOF文件越来越来,需要定期重写来压缩AOF文件
- 重新加载(reload): 通过加载AOF文件来恢复数据
- fsync策略
- appendfsync always:
主线程调用write执行完成后,后台线程(aof_fsync线程)立马调用fsync函数进行同步 (
write + fsync) - appenfsync eversec:
主线程调用write执行完成后,后台线程(aof_fsync线程)每秒调用fsync函数进行同步(
write + 1秒 + fsync) - appendfsync
no:主线程调用write执行完成后,由操作系统决定什么时候调用fsync函数进行同步(
write 不 fsync ,操作系统决定,Linux一般是30秒)
- appendfsync always:
主线程调用write执行完成后,后台线程(aof_fsync线程)立马调用fsync函数进行同步 (
- rewrite
- 通过读取当前数据库的状态,然后生成一个新的AOF文件来替换旧的AOF文件
- 同时维护了一个AOF重写缓冲区,以记录创建过程中出现的写命令,等创建完成后,将写命令追加到新的AOF文件中
- 通过
BGREWRITEAOF命令来触发重写操作,会创建一个子线程进行重写操作
- 混合(RDB+AOF)
- 使用
aof-use-rdb-preamble命令开启混合持久化,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头,但会导致可读性较差.
- 使用
- 如何选择持久化
- 数据安全性要求高,选择RDB+AOF同时开启或者混合模式
- 数据安全性要求不高时,选择RDB
- 不建议只开启AOF,不易备份或快速重启恢复
- 快照(snapshotting,RDB)
Redis内存管理策略
- 过期数据存储方式
- 通过字典(redisDb)来存储key的过期时间,由dict属性存储键值对,expires属性存储过期时间
- 过期数据删除策略
- 惰性删除
- 用到key时检查,是否需要删除.但会导致堆积过多过期key
- 定期删除
- 隔一段时间抽取一批key检查,是否需要删除.
- 惰性删除
- 内存淘汰机制
- volatile-lru: 淘汰最近最少使用的数据 (已设置过期时间)
- volatile-ttl: 淘汰要过期的数据 (已设置过期时间)
- volatile-random: 随机淘汰数据 (已设置过期时间)
- allkeys-lru: 内存不足时,淘汰最近最少的数据 (全部)
- allkyes-random: 内存不足时,随机淘汰数据 (全部)
- no-eviction: 禁止写入数据
- volatile-lfu: 淘汰最不经常使用的数据 (已设置过期时间)
- allkeys-lfu: 淘汰最不经常使用的数据 (全部)
- 过期数据存储方式
Redis生产问题
- 缓存穿透
- 访问大量无效key,透过缓存,直接请求数据库
- 解决方案
- 缓存无效key
- 布隆过滤器
- 接口限流,IP黑名单
- 缓存击穿
- 缓存的热点数据过期或不存在,大量请求数据库
- 解决方案
- 缓存key时间设置比较长
- 提前预热热点数据
- 缓存雪崩
- 同一时间,大量缓存数据失效,大量请求数据库
- 解决方案
- 多级缓存
- 限流
- 缓存预热
- 缓存数据库一致性
- 旁路缓存模式: 先更新数据库,再删缓存.
- 增加缓存更新重试机制: 隔断时间重试删除缓存,或者引入消息队列来删缓存(删除缓存消息写入mq,mq来重试删除.)
- 缓存穿透
Redis集群
- Redis 多集群:主从模式,一主多从 (端口:6379)
- 优点: 简单
- 缺点: 需要手动维护主节点信息,发生故障需要手动恢复
- Redis Sentinel:哨兵模式,一主多从,三哨兵 (端口:26379)
- 优点: 在主从模式的基础上,增加哨兵节点,以维护Redis节点状态,自动故障转移
- 缺点: 不好动态扩容
- 常见问题
- 有什么作用
- 监控:监控所有Redis节点状态
- 故障转移:如果master出现异常,Sentinel会实现故障转移,将一台slave升级成master
- 通知:通知新的master连接信息给slave,让它们执行replicaof成为新的master的slave
- 配置提供:通知新的master连接信息给客户端
- 检测节点是否下线
- 主观下线:某个Sentinel节点认为Redis节点下线(PING请求,PONG(LOADING/MASTERDOWN)超过响应时间)
- 客观下线:超过半数Sentinel节点认为Redis节点下线
- 如何选举新的master节点
- slave在线: 节点必须在线
- slave优先级:通过slave-priority设置优先级,最高的成为master,没有优先级就看复制进度
- 复制进度:数据最完整,复制进度最快的slave成为master
- runid: 如果优先级和复制进度一样,则runid最小的成为master
- Sentinel如何选举Leader
- 通过Raft算法选举出Leader
- Sentinel可以防止脑裂吗
- 发生网络隔离(也就是脑裂)时,master必须能写入slave,并能从节点得到响应。否则就拒绝接受新的写入命令
- 有什么作用
- Redis Cluster:切片集群,三主三从(端口:6379和16379)
- 优点: 官方推荐,提供主从复制、故障转移功能,很⽅便地进⾏横向拓展,动态扩容和缩容是其最⼤的优势
- 缺点: 需要多服务器,适合数据量大,并发量⼤的场景
- 常见问题
- 如何分片
- Redis使用哈希槽分区,每个键值对属于一个哈希槽.
哈希槽 = key ^ CRC-16 % 16384
- Redis使用哈希槽分区,每个键值对属于一个哈希槽.
- 如何找到对应的哈希槽
- 根据Key通过上面的计算公式找到对应的哈希槽,然后再查询哈希槽和节点的映射关系
- 如果是当前节点负责就返回响应结果
- 如果不是则发送重定向错误,告诉客户端当前的哈希槽由哪个节点负责
- 客户端则向目标节点发送请求并更新缓存的哈希槽分配信息
- 为什么哈希槽是16384个(2^14)
- 哈希槽太大会导致心跳包变大,消耗带宽
- 哈希槽总数越少,对存储的哈希槽信息的bitmap压缩效果好
- 16384个槽节点占用空间2k(16384/8),空间小,并且不太会超过1000个主节点,完全够用
- Redis Cluster 扩容缩容
- 扩容缩容的本质是重新分片,动态迁移哈希槽
- 提供重定向机制(ASK|MOVED),在发生扩容缩容时,仍能对外提供服务
- Redis Cluster 节点通信
- Cluster 各个节点使用Gossip协议通信,每个节点都维护了一份集群的状态信息
- Cluster 内置了Sentinel机制,通过Gossip协议相互探测健康状态,发生故障自动切换
- 如何分片
- Redis 多集群:主从模式,一主多从 (端口:6379)
一致性哈希:
分布式
分布式共识算法
- CAP理论
- C|Consistency: 一致性, 所有节点访问同一份最新的数据副本
- A|Availability: 可用性, 非故障节点在合理时间返回合理的响应
- P|Partition Tolerance: 分区容错性,当出现网络分区时,仍能对外提供服务
- 一般时CP或AP架构,当发生网络分区时,P是一定需要保证的.选择CP还是AP就看业务场景
- 但没有发生网络分区时,CA是能同时保证的.
- CP架构: ZooKeeper | AP架构: Eureka | CP&AP架构: Nacos
- BASE理论
- BA|Basically Available:基本可用, 允许损失部分可用性
- S|Soft-state:软状态, 允许系统存在中间状态,且不会影响系统整体可用性
- E|Eventually Consistent:最终一致性, 系统中的所有数据副本在经过一段时间同步后,最终会达到一致的状态.
- 当发生网络分区时,要保证AP时,会放弃C,而BASE理论则是不保证强一致性,但要保证最终一致性.是对AP方案的补充.
- Paxos算法
- Basic Paxos:多节点就value达成共识
- 三种角色
- 提议者:接受客户端请求,发起提案(提案ID和提案value)
- 接受者:对提案进行投票,同时记住投票历史
- 学习者:超过半数投票的提案将会被执行运算,并发送给客户端
- 三种角色
- Multi Paxos:执行多个Basic Paxos
- Basic Paxos:多节点就value达成共识
- Raft算法
- 拜占庭将军:在会出现故障或叛变节点时,需要保证系统的整体可用性
- 共识算法:即使面对故障,服务器也可以在共享状态上达成一致
- 基础
- 节点类型:某一时间,节点一定会是以下的身份类型
- Leader:负责发起心跳,响应客户端,创建日志,同步日志
- Candidate:发起竞选(Follower竞争Leader产生的临时角色)
- Follower:接受Leader的心跳和日志同步数据,投票给Candidate
- 任期:每次选举的开始就是一次任期(term),如果没有选出Leader将会开启下个任期和选举
- 日志:
- log = entry<term,index,cmd>[] ;
- 日志由entry数组构成,每一个事件成为一个entry,只有Leader可以创建entry;
- term = 任期;index = enry在log中下标;cmd = 应用到状态机的操作;
- 节点类型:某一时间,节点一定会是以下的身份类型
- 领导人选举:
- 使用心跳机制来触发选举,超过半数投票的Candidate获得选举,成为Leader
- Follower会自增term号并转换状态为Candidate,并向其他节点发起RequestVoteRPC请求,直到有Leader出现或进行下一轮选举
- 避免出现无限重复投票的情况,采用选举随机超时策略,增加一个选举随机超时时间
- 日志复制:Leader 和 Follower 的日志需要保持一致,不一致时会删除Follower不一致的地方,将Leader记录的后续日志发给Follower
- 安全性
- 选举限制
- 节点崩溃
- 时间与可用性
- Gossip协议:分散式发散消息
- 集中式发散消息:一个节点向其他节点共享信息
- 分散式发散消息:每个节点周期性随机向其他节点共享信息
- Redis Cluster 采用
Gossip协议来进行共享信息,每个节点都维护了一份Redis集群的状态信息 - 消息传播模式
- 反熵:消除不同节点的数据差异,提高节点相似度,从而降低熵值(不确定性)
- 传谣(谣言传播):一个节点一旦有了新数据就成为了活跃节点,活跃节点周期性向其他节点发送新数据,直到所有节点都有了新数据
- 差异:
- 反熵用于传播所有数据,传谣用于传播新数据
- 反熵一般需要设计一个闭环,传谣适合节点数量更多和动态变化的场景
- CAP理论
API网关:请求转发 + 请求过滤
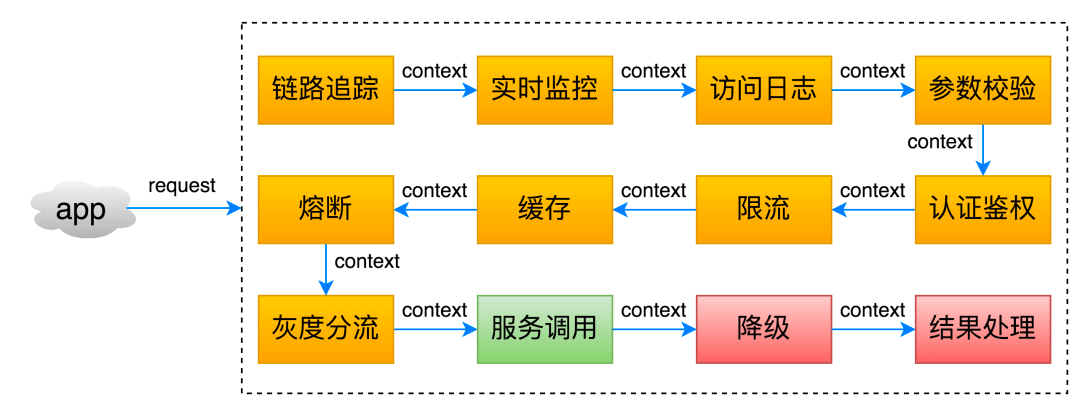
Netflix Zuul
- Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网关必备的各种功能
Spring Cloud Gateway
Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求
工作流程
- 路由判断(Predicate):先经过Gateway Handler Mapping处理,经过Predicate判断符合哪个路由规则,再映射到后端服务
- 请求过滤(Pre-Request):然后请求到达Gateway Web Mapping处理,经过Filter Chain进行拦截和修改( 增加请求头、参数校验),再转发请求到后端服务
- 服务处理(Handler):后端处理请求
- 响应过滤(Post-Request):后端处理请求完成后,返回给Gateway再次经过Filter Chain进行处理,再响应给客户端
- 响应返回:过滤处理完成后,响应给客户端
Predicate
- 断言配置:满足断言的条件后,就能映射到指定的服务

动态路由:使用Nacos Server和Spring Cloud Alibaba Nacos Config实现动态路由,自动感知配置变化,动态配置网关信息
Filter
Pre:请求到服务前,对请求进行拦截和修改,如参数校验,权限校验,流量监控,日志输出,协议转换等
Post:请求处理完成后,对响应内容进行修改,如修改响应头、日志输出、流量监控
限流:Sentinel 模块实现限流,提供两种资源维度的限流:route 维度和自定义 API 维度
全局异常处理:实现ErrorWebExceptionHandler的Handle方法
OpenResty
- OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,通过简单的 Lua 语言来扩展网关的功能,比如实现自定义的路由规则、过滤器、缓存策略等
Kong
- 基于OpenResty(Nginx + Lua),由Kong Server、Apache Cassandra/PostgreSQL、Kong Dashboard组成,本身就是一个 Lua 应用程序
APISIX
- 基于 OpenResty 和 etcd
Shenyu
- 基于 WebFlux
分布式ID
- 基本要求
- 全局唯一:ID 全局唯一性
- 高性能:生成速度要快
- 高可用:生成服务要可用
- 方便易用:拿来即用
- 解决方案
- 数据库主键自增(MySQL、Redis):MySQL号段模式,Redis incr指令
- UUID、Snowflake(雪花算法):生成速度快,ID有序,比较灵活但有可能出现时钟回拨导致重复ID问题
- UidGenerator:对雪花算法进行了改进,QPS更高,但18年后不再维护
- Leaf:支持号段模式和雪花算法,支持双号段,解决了时钟回拨问题,QPS 压测结果近 5w/s
- Tinyid:基于数据库号段模式,支持双号段,纯本地操作,无 HTTP 请求消耗
- IdGenerator:兼容所有雪花算法,解决了时钟回拨问题,不依赖外部存储系统,支持多语言调用
- 基本要求
分布式锁
基本要求
- 互斥:任意一个时刻,锁只能被一个线程持有
- 高可用:当一个锁服务出现问题,能够自动切换到另外一个锁服务;即 锁一定会被释放
- 可重入:节点可重复获取锁
- 高性能:快速获取或释放锁
- 非阻塞:拿不到锁不能无限等待
解决方案
MySQL实现
- 通过唯一索引或排它锁实现,但有性能差、不具备锁失效等机制
Redis
lua + setnx指令获取简易锁1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16# KEYS[1]-lockKey, ARGV[1]--requestId, ARGV[2]--expire if redis.call('setNx', KEYS[1], ARGV[1]) == 1 then if tonumber(ARGV[2]) > 0 then redis.call('expire', KEYS[1], ARGV[2]) end return 1 else if redis.call('get', KEYS[1]) == ARGV[1] then if tonumber(ARGV[2]) > 0 then redis.call('expire', KEYS[1], ARGV[2]) end return 1 else return 0 end endlua + del指令释放简易锁1 2 3 4 5 6# 释放锁时,先比较锁对应的 value 值是否相等,避免锁的误释放 if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 endRedisson:锁的优雅续期
- 使用
Watch Dog来监控和续期锁,执行未完成,每隔10秒就执行续期操作,将超时时间设置为30秒 - 内置了可重入锁、自旋锁、公平锁、多重锁、红锁、读写锁
- 使用
Zookeeper
基于
临时顺序节点和Watcher(事件监听器)实现,推荐使用 Curator 来实现 ZooKeeper 分布式锁,是Netflix开源的ZooKeeper Java框架1 2 3 4 5 6// 分布式可重入排它锁 InterProcessLock lock1 = new InterProcessMutex(client, lockPath1); // 分布式不可重入排它锁 InterProcessLock lock2 = new InterProcessSemaphoreMutex(client, lockPath2); // 将多个锁作为一个整体 InterProcessMultiLock lock = new InterProcessMultiLock(Arrays.asList(lock1, lock2));获取锁
1lock.acquire(10, TimeUnit.SECONDS)释放锁
1lock.release()
Etcd
分布式事务
- CAP基础理论和BASE理论
- 一致性
- 强一致性:写什么读到的就是什么
- 弱一致性:不一定能读到最新值,只能在某个时刻能达到数据一致
- 最终一致性:保证一定时间内达到数据一致
- 柔性事务:追求最终一致,是BASE理论+业务实践,如TCC、Saga、MQ事务、本地消息表
- TCC(补偿事务)
- Try 尝试阶段:尝试执行。完成业务检查,并预留好必须的业务资源
- Confirm 确认阶段:确认执行。当所有参与者Try阶段执行成功时,就会执行Confirm,并处理预留的业务资源
- Cancel 取消阶段:取消执行,释放Try预留的业务资源
- 常见框架:ByteTCC、Seata、Hmily
- Saga
- 长事务解决方案,将长事务拆分成多个本地短事务,每个短事务都会有个补偿动作,执行失败会恢复
- MQ事务
- RocketMQ:两阶段提交,超过最大重试次数,放入死信队列,手动处理,如果消息队列挂掉,数据库事务无法执行
- QMQ:本地消息表,将分布式事务拆分成本地事务,即使消息队列挂掉也不影响数据库执行
- TCC(补偿事务)
- 刚性事务:追求强一致,如2PC、3PC
- 2PC(两阶段提交)
- 准备阶段:事务管理者向参与者询问本地事务操作是否执行成功,根据结果并不执行提交事务,而是进行提交阶段
- 提交阶段:事务管理者向参与者询问提交事务操作是否执行成功,根据结果来执行提交或回滚操作,完成后会结束当前分布式事务
- 存在问题
- 同步阻塞:事务阶段会一直占用相关资源,导致阻塞
- 数据不一致:网络问题导致部分参与者收不到comitt/rollback情况时,会导致数据不一致
- 单点问题:管理者挂掉会导致参与者一直卡在提交阶段
- 3PC(三阶段提交)
- 询问阶段:询问参与者能否执行本地数据库操作
- 准备阶段:当所有参与者都可执行时,才会执行本地事务操作,然后继续2PC阶段的步骤
- 提交阶段:同2PC阶段步骤
- 引入超时机制避免出现一直阻塞
- 2PC(两阶段提交)
分布式配置中心
- Spring Cloud Config
- Nacos
- Apollo
RPC
- 角色
- 客户端(服务消费端):调用远程方法的一端
- 客户端Stub(桩):代理类,将调用的类、方法、方法参数等传递到服务端
- 网络传输:将调用的信息传递到服务端,然后将服务器执行的结果返回给客户端
- 服务端Stub(桩):服务端实际收到请求后,执行对应的方法并返回结果给客户端
- 服务端(服务提供端·):提供远程方法的一端
- 原理
- 客户端(Client)以本地方式调用远程服务
- 客户端Stub收到调用后,将类、方法、方法参数组装成能进行网络传输的消息体(序列化):RpcRequest
- 客户端Stub找到远程调用的地址,并将消息以序列化方式发送到服务提供端
- 服务端Stub收到消息将消息反序列化为Java对象:RpcRequest
- 服务端Stub根据RpcRequest的类、方法、方法参数调用本地方法
- 服务端Stub得到方法执行结果并将其组装成进行网络传输的消息体(序列化):RpcResponse
- 客户端Stub接收到消息,并将其反序列化成为Java对象,得到最终结果
- 解决方案
- Dubbo
- Motan
- gRPC
- Thrift
- 角色
Nacos | ElasticSearch | Kafka
Nacos
ElasticSearch
Kafka
- 消息模型:发布-订阅模型
- 使用主题(Topic)作为消息通信载体,通过主题传递给所有订阅zhe
你还有什么要问我的吗
- 同级:能不能谈谈你作为⼀个公司⽼员⼯对公司的感受?
- 领导:
- 部⻔的主要⼈员分配以及对应的主要⼯作能简单介绍⼀下吗?
- 未来如果我要加⼊这个团队,你对我的期望是什么?
- boss: 贵公司的发展⽬标和⽅向是什么?
GC 日志
2024-03-23T10:15:23.123-0800: 1.234: [GC (Allocation Failure) [PSYoungGen: 65536K->16384K(76288K)] 65536K->32768K(251392K), 0.0157545 secs] [Times: user=0.02 sys=0.01, real=0.02 secs] 2024-03-23T10:15:25.456-0800: 3.456: [GC (Allocation Failure) [PSYoungGen: 81920K->20480K(76288K)] 98304K->57344K(251392K), 0.0196028 secs] [Times: user=0.02 sys=0.01, real=0.02 secs] 2024-03-23T10:15:27.789-0800: 5.789: [Full GC (Ergonomics) [PSYoungGen: 20480K->0K(76288K)] [ParOldGen: 36864K->49152K(175104K)] 57344K->49152K(251392K), [Metaspace: 20480K->20480K(1067008K)], 0.1056299 secs] [Times: user=0.11 sys=0.01, real=0.11 secs] 2024-03-23T10:15:30.123-0800: 8.123: [GC (Allocation Failure) [PSYoungGen: 65536K->16384K(76288K)] 114688K->81920K(251392K), 0.0257884 secs] [Times: user=0.03 sys=0.01, real=0.03 secs] 2024-03-23T10:15:32.456-0800: 10.456: [GC (Allocation Failure) [PSYoungGen: 81920K->20480K(76288K)] 139264K->106496K(251392K), 0.0212413 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] 2024-03-23T10:15:34.789-0800: 12.789: [Full GC (Ergonomics) [PSYoungGen: 20480K->0K(76288K)] [ParOldGen: 86016K->90112K(200704K)] 106496K->90112K(251392K), [Metaspace: 20480K->20480K(1067008K)], 0.1468552 secs] [Times: user=0.14 sys=0.01, real=0.15 secs]